Conflict Elision in Serializability
Conflict Elision
Databases classes also teach conflict serializability from the most conservative perspective, where read-after-write, write-after-read, and write-after-write conflicts are always checked. But in real world systems, serializable databases frequently seem to break the exact rules of conflict serializability one is taught such systems must uphold:
-
Spanner permits concurrent writes to the same item via shared writer locks, which implies it doesn’t check write-write conflicts.
-
FoundationDB only checks write-after-read conflicts.
-
CockroachDB doesn’t check read-after-write conflicts.
These databases each elide one or more forms of conflict checking, and yet these databases are still correct in describing themselves as serializable! To understand conflict elision, we approach the topic from the opposite direction: what does considering each type of conflict enable in terms of operation reordering?
The Power of Conflicts
Our golden rule is that two operations may only be swapped if we know that they do not conflict. In the absence of conflict information, we have no idea if two
Write-Write Conflict Elision
Accordingly, write-write conflicts are the most frequently elided form of conflicts.
Thomas write rule.
In multi-version concurrency control, all writes for a transaction appear in the same version, and thus are always appended onto the history of operations in one large group. It’s impossible for two individual operations from two transactions to interleave. If one never tries to re-order entire transaction groups worth of writes, then there’s no need to ever pay attention to write-write conflicts.
Formally, such a property is called "write snapshots", and was introduced in "A critique of snapshot isolation".
As a last note before we move on, there’s a consistent theme in serializability, and concurrency control in general, that one is allowed to break any rule at any time as long one can ensure that a user will never be able to prove that a rule was broken.
An often taught, but seldom used way to break the rules of write-write conflicts are allowing commutative operations to be freely reordered. For example, any ordering of increments and decrements result in the same final value, and so enforcing an order on them isn’t necessary if one can never witness the intermediate values. This is what increment locks permit, or more generally, escrow transactions.
In the context of our operation swapping game,
Read-After-Write Conflicts
Read-after-write conflicts are all about writes moving to the right or reads moving to the left in our version diagram.
Of the three, these are the most commonly elided conflicts, but they’re still possible. SQL constraint checking might need to do reads, writes, reads. The latter reads could move backwards. The former reads could move forwards.
Write-After-Read Conflics
It’s very common for reads to be serialized later than when they were performed. These
I Can’t Believe It’s Not Serializability
Lastly, there’s times that serializable database do un-serializable things, and still rightfully get to claim that they’re serializable. The trick, is that a user can never see that the execution was unserializable.
Increment locks
escrow transactions.
Architecting for Conflict Elision
For this post, our mental model of a database is that it records the (transaction, operation, item) tuple for each read and write that it processes, in the order that they happen. When a transaction wishes to commit, the database filters the history of operations down to the ones from committed transactions or from the committing transaction, and then asks our serializability testing procedure "is this new history of operations serializable?". If so, it means the transaction is allowed to commit, if not, the transaction is aborted and all operations are removed from the history (and any if any transactions exist which read its uncommitted writes, they are also aborted).
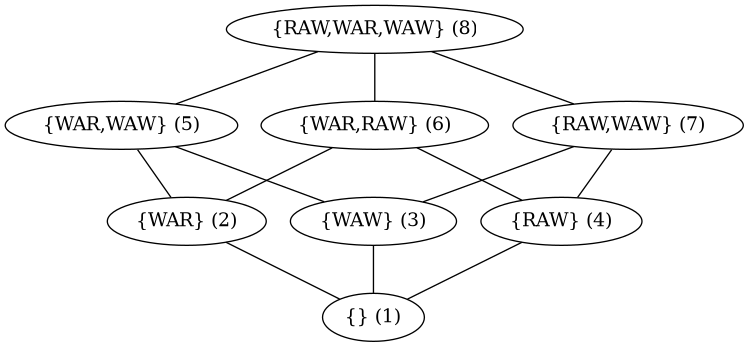
The database is in control of when it allows an operation to execute, and thus at what point in the history it is inserted. It could be appended onto the end, it could be placed anywhere in the middle. By enforcing varying rules about when, where, and how operations are executed and placed into the history, the database is able to promise that it will prevent certain types of transaction conflicts from occurring at all, and so the serializability validation procedure may trivially assume they don’t exist. This post is about when we can not check certain types of these conflicts. Combining them gives us a lattice, and for each combination, we’ll consider a hypothetical system for which that combination of conflicts is the correct and minimal set of conflicts which need to be validated.
The Lattice of Conflict Checking Databases
We’ll be looking at each of these cases through the lens of the operation reordering game. The required result for each case is that for any input transactions, the final schedule of operations must be trivially a serializable history of operations. We’ll achieve this by placing a set of restrictions on how or when the database is allowed to execute operations and an inverse set of restrictions on what combinations of operations may be safely swapped. The two sides compensate for each other — the more concurrently we allow the database to execute operations from transactions, the more conflict information we need to track to know what operations can be safely swapped. The more restrictions the database has on its concurrency, the less conflict information we need to track for the operation swapping.
(1) Check Nothing / Elide Everything
To reiterate, serializability is defined as a history of operations which is equivalent to executing each transaction in some sequential order. A system may thus trivially enforce serializability by only executing transactions one at a time, sequentially. No extra conflict checking is needed to be able to say that such a system is serializable. This is not as ridiculous as it might sound. Calvin (and all of its variants), VoltDB, and TigerBeetle all adopt this model by ordering transactions first, and then executing each transaction to completion, in that order.
In the context of our operation reordering game, the database promises that every time it adds a new transaction, it appends all of the transaction’s reads and writes in one contiguous grouping. Our operation swapping function is a no-op.
(2) Check WAR / Elide WAW & WAR
T1.R(X) T2.W(X) Conflict: T2 must commit after T1 T1.R(X) T2.W(Y) No Conflict: Equivalent to T2.W(Y) T1.R(X)
Checking Write-After-Read conflicts means that we’re allowed to exchange two operations where the operation on the left is a read, and the operation on the right is a write. Thus, Write-After-Read conflicts are about moving reads forward in version-time, and moving writes backwards in version time.
This is one of the most commonly encountered sets of conflict elisions. If all reads are performed before all writes, then we’ll only ever need to swap writes forward or writes backwards for the two to meet. The decision of moving reads to the commit timestamp or moving writes to the read timestamp is up to the database. Moving reads for
(3) Check WAW / Elide WAR & RAW
By considering write-write conflicts, we are allowed to re-order writes in the operation history, because the system records when it’s not safe to (via recording the write-write conflict). It’s always safe to swap the order of two writes to different keys, but that swapping the order of two writes to the same key might result in unserializable behavior.
I like to think of write-write conflicts as the defenders of transaction atomicity. Given two transactions $T_1$ and $T_2$, which each perform a write to $X$ and a write to $Y$, we can only break atomicity by allowing writes from the two transactions to be interleaved:
Not Serializable: T1.W(X) T2.W(X) T2.W(Y) T1.W(Y)
Ending state: T2's X. T1's Y.
Serializable: T1.W(X) T1.W(Y) T2.W(X) T2.W(Y)
Ending state: T2's X. T2's Y.
And so write-write conflicts are preventing the database from reaching a state where a subsequent read of all values in the database would not be serializable.
(4) Check RAW / Elide WAW & WAR
T1.W(X) T2.R(X) Conflict: T2 must commit after T1.
Checking RAW conflicts means that we’re permitted to swap a write and a read, where the read occurs after the write, and the read and the write are on different items.
This importantly allows reads to be pulled backwards in the ordering, or writes to be pulled forwards. Generally, this alone isn’t a particularly useful way to be able to swap operations. In most transactions, the reads are performed before the writes, and thus one would always wish to move reads forward or writes backward.
Allow us to instead consider a database based around financial transactions[1]. The database supports one form of transaction: apply an increment to one account, a decrement to another, and ensure that the decremented account doesn’t drop below zero. One could implement such a system by first logging the increment and decrement operations, and then issuing a read through the levels of an LSM, collecting other increment and decrement operations, until it reaches a final value and sums all discovered operations. If the read encountered any (other) uncommitted increments or decrements, then establish a transaction dependency on the uncommitted transaction. If the read returns a greater-than-zero value, swap the read operation with other reads and writes in the history until it reaches the write
[1]: I swear I’m not referencing TigerBeetle.
(5) Check WAR & WAW / Elide RAW
Read Snapshots
(6) Check WAR & RAW / Elide WAW
Write Snapshots
(7) Check RAW & WAW / Elide WAR
(8) Check Everything / Elide Nothing
single version database
Rules to Live By
Rules for Write-After-Write Conflicts
You do need to check write-after-write conflicts if:
-
Your writes are performed across a range of versions OR it is a single-version database.
-
You are implementing SQL isolation levels, which mandate write-after-write conflict checking as part of the "lost update" anomaly restriction.
You do not need to check write-after-write conflicts if:
-
Writes all appear atomically in the same version. (e.g. with MVCC)
-
The "writes" are commutative operations (e.g. increment), or you implement escrow transactions.
Rules for Read-After-Write Conflits
You do need to check read-after-write conflicts if:
-
Reads are performed across a range of versions OR it is a single-version database.
-
At commit, reads can be serialized at an earlier version than when they were performed.
-
At commit, writes can be serialized at a later version than when they were performed.
Rules for Write-After-Read Conflicts
You do need to check write-after-read conflicts if:
-
Your reads are performed across a range of versions OR it is a single-version database.
-
At commit, reads can be serialized at a later version than when they were performed.
-
At commit, writes can be serialized at an earlier version than when they were performed.
Not all serializability is equal
serializability classes
history vs scheduler
2PL restrictive SSI less restrictive serializable safety net
See discussion of this page on Reddit, Hacker News, and Lobsters.